RESEARCH PROFILE
In my research I have mainly taken a variationist approach to statistically modeling linguistic variation within and across non-standard or post-colonial varieties of English. While I have mostly relied on corpus data and used R and RStudio to investigate linguistic phenomena, I have also used questionnaire designs and engaged in acoustic analyses of audio data using, for example, the Bavarian Archive for Speech Signals’s The Munich Automatic Segmentation System (MAUS) and PRAAT to investigate target language proximity in vowel production by non-native speakers of English. My position as associate professor at the Arctic University of Norway has allowed me to gain experience in experimental methods including, e.g. (web-based) eye-tracking and analyzing data obtained from experimental designs. I am also developed an interest in language documentation, anthropological linguistics, and field work methods.
One basic issue underlying my research has been to investigate how, why, and to what extent social, cultural, and psychological factors impact linguistic behavior. The aim of these analyses does, however, not merely focus on describing differences between speakers with distinct social profiles but to elucidate mechanisms underlying processes of language change. Thus, in essence, I address questions concerning how innovative features spread through speech communities and by which mechanisms these innovations take over from traditional variants. In this line of research, I have become particularly interested in how semantically bleached elements, such as discourse particles but also degree adverbs (intensifiers), correlate with social, cultural, and psychological factors. For instance, an article for which I have won the ISLE Richard M. Hogg Prize in 2015 investigated whether traditional variationist variables and psycholinguistic factors correlate with the use of the discourse particle eh in New Zealand English. The underlying question concerning priming as a psycholinguistic variable was to elaborate on the role that priming may potentially play in cases of ongoing language change.
A more recent focus of my work lies in the analysis of discourse on social media and combining linguistic methods with insights from digital media studies. This research interest is visible, for instance, in my recent publication on the Twitter discourse around COVID-19 in Australia. Another, broader, interst of mine is reproducibility and best practices in resarch. To this end, I have given talks, for example my plenary at ICAME42, and organized workshops to raise awareness of potentially problematic research practices, showing how suboptimal practices can affect reserach quality, and offering guides on how to implement best practices and sustainable workflows when dealing with language data.
DIGITAL HUMANITIES
In 2019, I was a Digital Champion on behalf of the Australian Data Research Commons (ARDC) and I am continuing to promote the use of digital methods in HASS (Humanities, Arts and Social Sciences) by offering workshops on computational methods and giving talks about best practices in research data management and research methodology.
In my current role as Lecturer in Applied Linguistics at the School of Languages and Cultures, I have established the Language Technology and Data Analysis Laboratory (LADAL). The LADAL LADAL (pronounced lah’dahl) is a free, open-source, collaborative support infrastructure for digital and computational humanities established 2019 by the School of Languages and Cultures at the University of Queensland. LADAL aims at assisting anyone interested in working with language data in matters relating to data processing, visualization, and analysis and offers guidance on matters relating to language technology and digital research tools. To this end, LADAL offers introductions to topics and concepts related to digital and computational humanities, online tutorials, interactive Jupyter notebooks, and events including workshops and webinar series. We are currently working on improving the interactivity of LADAL and adding more online tutorials, video introductions and screen casts that focus on a wide variety of topics and methods in Computational Humanties, data visualization and analytics (statistics), as well as computational linguistics and Text Analysis.
Before working in Australia and Norway, I was an associate at the Language Technology Group of the department for computer sciences at Universität Hamburg which allowed me to further develop my expertise in computation. To this end, I have very good command of R – a programming environment which is extremely versatile and a very powerful tool for linguistic data analysis, text mining, and sophisticated statistical modeling. I use R in my research to retrieve, clean, process, visualize and statistically analyze data. The advantage of R is that it is an open source software that comes free of cost, is relatively easy to learn, and is supported by a large community of users and developers. Furthermore, knowledge of R or similar programming environments such as Python, which I have also used in the past, allows researchers to share their code and thus enable others to replicate studies step by step and thus improve transparency of research. In addition, I followed courses in human-machine interaction at the Computer Science department at Universität Hamburg before becoming an associate member of the Language Technology Group at that department in 2018.
Furthermore, I have experience in using PRAAT, a software package for acoustic analyses, to analyze speech and SurveyMonkey as well as GoogleForms to create online questionnaires. With respect to teaching, I have experience with various online learning platforms and I have created an e-learning course on corpus linguistics for which I have compiled specialized corpora that were designed to enable students to improve their ability to properly use academic English in their written English skills.
METHODOLOGICAL COMPETENCIES
In terms of methodology, my research has mainly built on quantitative analyses of corpus data or computational analyses of speech but I have also used qualitative analyses, yet to a lesser degree. With respect to statistical analyses, I have specialized on multivariate regression models (both fixed- and random effect models) and tree-based models (Random forests and Boruta) which allow to test the impact that independent variables and interactions between variables have on some dependent variable and can also be utilized in machine learning and AI applications as classifiers and variable-selection procedures. Furthermore, I have substantive experinece in applying exploratory classification or dimension-reduction and agglomerative methods, e.g. cluster analyses or Semantic Vector Space Models.
ACTIVITIES IN THE SCIENTIFIC COMMUNITY
I am member of various academic societies, e.g. The International Society for the Linguistics of English (ISLE), the Societas Lingustica Europaea (SLE), the Deutsche Gesellschaft f{\“ur Sprachwissenschaft (DGfS), and I am an affiliate member of the Australian Center of Excellence for the Dynamics of Language (CoEDL) among others. I regularly present findings from my research at conferences and actively try to publish results stemming from my research in internationally visible formats. In addition, I have organized conferences that are specifically targeted at younger researchers such as the Linguistics Colloquium of Northern Germany (NLK). In addition, I am currently organizing ISLE VII (7th meeting of the International Society for the Linguistics of English) together with Prof. Dr. Kate Burridge that will take place in Brisbane in 2023.
RESEARCH PROJECTS
1. Language Data Commons of Australia HASS RDC (LDaCA-RDC)
Large collections of language data have been amassed in Australia. Some data is in well-established archives (Trove), but much is in repositories which are more ephemeral because they have no long-term funding. The aim of establishing a Language Data Commons of Australia (LDaCA) is to federate these efforts into a nationally integrated research infrastructure for collections of high strategic importance for the Australian research community, and for translational research related to the national interest. LDaCA will be a sustainable long-term repository for ingesting and curating existing language data collections of national significance. In order to accomplish these aims, this project aims to: (1) establish a Governance Board of key stakeholders, (2) develop a comprehensive language data access policy framework, (3) develop shared technical infrastructure across institutions, (4) build a portal for discovery and access of language data, and (5) engage researchers and stakeholder communities with this infrastructure. These outcomes will open up the social and economic possibilities of Australia’s rich linguistic heritage and lay the foundation for the establishment of a broader HASS Research Data Commons.
Scheme: Humanities, Arts and Social Sciences (HASS) Research Data Commons (RDC) and Indigenous Research Capability Program (ARDC)
Role: CI & Advisory committee (Project lead: Michael Haugh)
Collaborators: Various Australian \& international stakeholders (researchers and institutions, e.g. universities, First Languages Australia, etc.)
Funding period: 2021-2028 (phase 1: 2021-2023/4, phase 2: 2024-2028/9)
2. Australian Text Analytics Platform (ATAP) (PL074)
Text analytics in Australian research happen at either a basic, generic level (handled with standard packages such as Antconc or Voyant Tools) or at a very specialised level with hand-crafted code. The aim of ATAP is to fill the space between these two possibilities where tools are needed which are more powerful than those at one end of the continuum, but more general than those at the other end. A key outcome of the project will be the development of an integrated notebooks-based platform for processing and mining text data.
Scheme: Australian Research Data Commons (ARDC) Platforms Program
Role: CI, Steering committee & Chair of the User Advisory Group (Project lead: Michael Haugh)
Collaborators: Various Australian & international stakeholders (researchers and institutions, e.g. universities, AARNet, etc.)
Funding period: 2021-2023
3. Acquisition, Variation, and Diachronic Change of English Amplifiier Systems
In this research project I focus on adjective-amplification in English and in contrast to my PhD dissertation which investigated discourse like in selected varieties of English, my habilitation project focuses on language acquisition, language variation and change, as well as historical linguistics rather than discourse pragmatics.
4. VowelChartProject
The VowelChartProject (Creating personalized vowel charts to improve target language pronunciation of English studies students) analyzed vowel formants of German, Russian, and Spanish learners of English in PRAAT to investigate where, why, and to what extent learners of English differ from native speakers of English with respect to vowel production and word final devoicing. What is particularly intriguing about this project is that it allows the quantification and objective measurement of the progress of ESL speakers with respect to their English language proficiency.
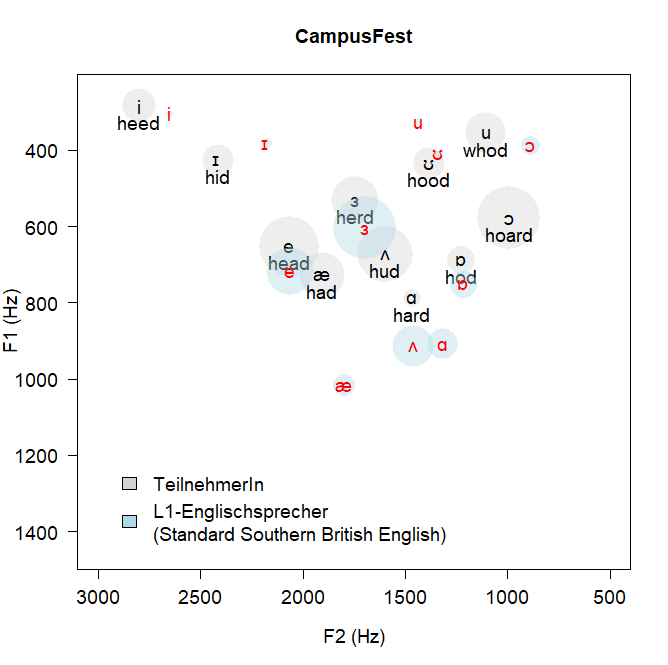
The data for this project consists of audio recordings of German, Spanish, and Russian learners of English who produce word lists and a short story to determine which vowels are acquired native-like, i.e. where there is a high degree of target language proximity, and which vowels pose more severe problems for learners of English, i.e. vowels which substantially deviate from native speakers‘ vowel production. After being recorded, students receive a personalized vowel chart depicting their F1 and F2 frequencies for English vowels. In addition, the F1 and F2 frequencies produced by native speakers are plotted alongside the German, Russian, and Spanish formants to allow for meaningful comparisons. The project has a high potential for future funding as it is a linguistic application that enhances language learning and can be adapted to languages other than English.
5. Language Documentation of Southern Low German
The project aims to create a speech corpus of one of the southernmost, as yet undocumented, varieties of Low German, Oberweserplatt, to enable the documentation of this variety shortly before extinction. The corpus will be created through field research and the use of (semi-)automated transcription and will represent usage data covering different registers, contain metadata about speakers and their relationships among each other, recording situations and text types.
6. Discourse-Pragmatic Variation and L1-Acquisition
I continue to work on discourse pragmatic variation and socio-linguistic determinants of the use of discourse like. As such, I am continuing research that evolved from my PhD dissertation by addressing questions involving the acquisition of variation and how linguistic innovations diffuse through the speech community. I am currently investigating at what age and in which order distinct functional variants of discourse like are acquired and whether extra-linguistic factors are acquired alongside the linguistic constructions themselves or whether the linguistic elements are acquired first and variation is acquired post-hoc.
(last updated 2022/04/12)
![]()